
找工作的故事
简单来说就是为了双方都确认自己的接受和发送都是正常的。
简单来说任何一方都可以在数据传输结束后发出释放链接的通知,需要对方确认后进入半关闭状态。当另一方也没有数据发送,也发出了释放链接的通知时,且对方确认后才真正关闭了TCP链接。
举个例子来说就是,A和B打电话,通过即将结束,A说:“我没什么要说的了“,B说:“我知道了”,然后B还没说完,巴拉巴拉说了半天,B又说:“好了,我说完了”,A说:“知道了”,最后挂断了电话。
cookie一般用来保存用户信息,比如:
- 我们在cookie中保存登录过的用户信息,下次访问的时候页面可以自动帮你登录的一些信息填写。
- 下次访问网站自动登录的功能一般都是存放了一个Token在cookie中。
- 登录后访问网站上的其他页面不需要获取登录
cookie数据保存在客户端,session数据保存在服务端,相对来说session更安全。
MySQL索引使用的数据结构主要是BTree索引和哈希索引。对于哈希索引来说,底层的数据结构是哈希表,因此在绝大多数需求为单条记录查询时,可以使用哈希索引,查询性能最快;其余大部分场景,建议使用BTree索引。
对于两种不同的存储引擎BTree的实现方式是不同的:
MyISAM:B+Tree叶节点的data域存放的是数据记录的地址。在索引检索的时候,首先按照B+Tree搜索算法搜索索引,如果Key存在,则取出data域的值,然后以data域的值为地址读取相应的数据记录。这种方式称为:非聚簇索引
InnoDB:其数据文件本身就是索引文件。相比MyISAM,索引文件和数据文件时分离的,其数据文件本身就是按B+Tree组织的索引结构,索引的Key时数据表的主键,因此InnoDB表数据文件本身就是主索引。这种方式称为:聚簇索引。
在根据主索引搜索时,直接找到Key所在的节点即可取出数据;根据辅助索引查找时,需要取出主键的值,再走一遍主索引。所以在设计表时,不建议使用过长的字段作为主键,也不建议使用非单调的字段作为主键,这样造成主索引频繁分裂。
MyISAM使用表级锁,InnoDB使用行级锁和表级锁,默认行级锁。
表级锁:MySQL中锁定粒度最大的一种锁。对当前整个表进行加锁,实现简单,资源消耗少,加锁快,不会发生死锁。锁定粒度最大,触发锁冲突的概率最高,并发度最低。
行级锁:MySQL中锁定粒度最小的一种锁,只针对当前操作的行进行加锁。锁定粒度最小,并发度高,但是加锁开销大,加锁慢,大大减少数据库操作的冲突,可能出现死锁。
Redis通过一个叫做过期字段来保存数据过期的时间。过期字段的键指向Redis数据库中的某个key,过期字典的值是long类型的整数,这个整数指向数据库键的过期时间。
Redis过期删除策略有两种:惰性删除和过期删除
惰性删除:只会在再次取出key时才进行过期检查,但是这样会造成太多key没有删除。
定期删除:每隔一段时间抽取一批 key 执行删除过期 key 操作。并且,Redis 底层会通过限制删除操作执行的时长和频率来减少删除操作对 CPU 时间的影响。
而Redis采用 定期删除+惰性/懒汉式删除 ,但是这样仍然会产生很多过期Key,长时间如此导致Out Of Memory,Redis是如何解决的呢?答案就是:内存淘汰机制。
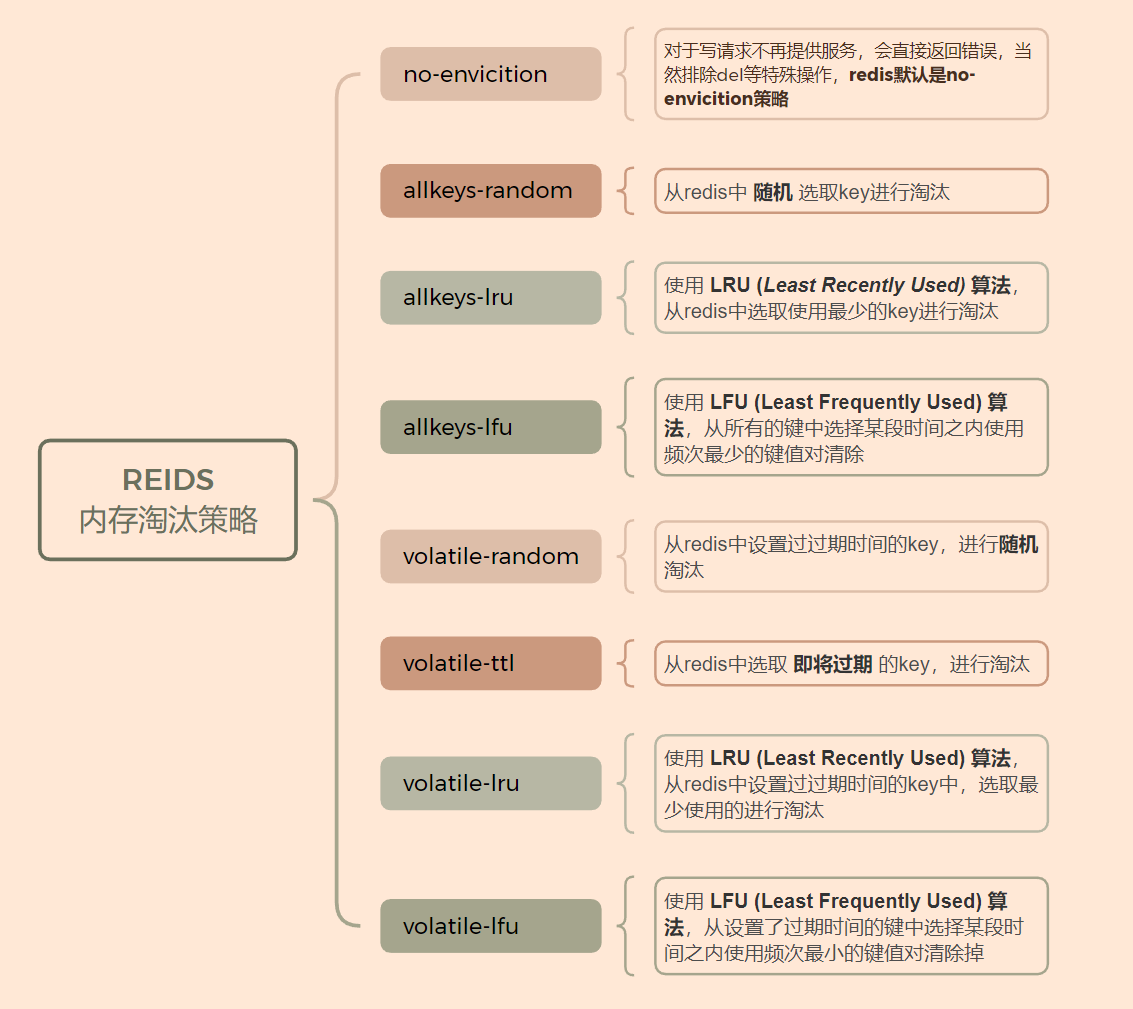
RANDOM:随机
TTL:从设置了过期时间的 Keys 中获取最早过期的一批 Keys
LRU:所有的 Keys 都根据最后被访问的时间来进行排序的,所以在淘汰时只需要按照所有 Keys 的最后被访问时间,由小到大来进行即可
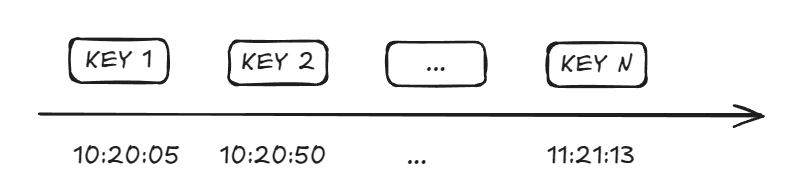
LFU:根据数据的历史访问频率来淘汰数据,其核心思想是“如果数据过去被访问多次,那么将来被访问的频率也更高”
LFU算法反映了一个key的热度情况,不会因LRU算法的偶尔一次被访问被误认为是热点数据
事务管理是应用系统开发中必不可少的一部分。Spring 为事务管理提供了丰富的功能支持。Spring 事务管理分为编程式和声明式两种。编程式事务指的是通过编码方式实现事务;声明式事务基于 AOP,将具体的逻辑与事务处理解耦。生命式事务管理使业务代码逻辑不受污染,因此实际使用中声明式事务用的比较多。所以说, spring 是使用 aop 来代理事务控制 ,是针对于接口或类的,所以在同一个 service 类中两个方法的调用,传播机制是不生效的。
声明式事务有两种方式,一种是在配置文件(XML)中做相关的事务规则声明,另一种是基于 @Transactional 注解的方式。以下介绍基于 @Transactional 注解的事务管理。
- 默认配置下(rollbackFor 属性不指定时) Spring 只会回滚运行时、未检查异常(继承自 RuntimeException 的异常)或者 Error。
@Transactional注解只能应用到 public 方法才有效。
事务的传播行为,使用propagation属性,默认值为 Propagation.REQUIRED。可选的值有:
- PROPAGATION.REQUIRED:如果当前没有事务,则创建一个新事务。如果当前存在事务,就加入该事务合并成一个事务。该设置是最常用的设置。
- PROPAGATION.SUPPORTS:支持当前事务,如果当前存在事务,就加入该事务。如果当前不存在事务,就以非事务执行。
- PROPAGATION.MANDATORY:支持当前事务,如果当前存在事务,就加入该事务,如果当前不存在事务,就抛出异常。
- PROPAGATION.REQUIRE_NEW:创建新事务,无论当前存不存在事务,都创建新事务。这个方法会独立提交事务,不受调用者事务影响,父级异常也是正常提交。
- PROPAGATION.NOT_SUPPORTED:以非事务方式执行操作,如果当前事务存在,就把当前事务挂起。
- PROPAGATION.NEVER:以非事务方式执行,如果当前存在事务,则抛出异常。即父级方法必须无事务。
- PROPAGATION.NESTED:如果当前存在事务,则在嵌套事务内执行(它将会成为父级事务的一个子事务,方法结束后并没有提交,只有等父事务结束才提交)。如果当前没有事务,则按 REQUIRED 属性执行。如果它异常,父级可以捕获它的异常而不进行回滚,正常提交。但是如果父级异常,它必然回滚,这是和
PROPAGATION.REQUIRE_NEW不同的地方。
![]()
Oracle JDK 是JDK被Oracle收购后二次开发的开源的工具包,Open JDK大概3个月一更新,Oracle JDK大概6个月一更新,所以Oracle JDK上要上的可能会现在Open JDK上试试水,所以Oracle JDK更稳定。
Integer i1 = 40;
Integer i2 = new Integer(40);
System.out.println(i1==i2);//false
//为什么呢?下面是源码
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);// <=注意这里
}
private static class IntegerCache {
static final int low = -128;
static final int high;
static {
// high value may be configured by property
int h = 127;
}
}Integer i1=40 这一行代码会发生装箱,也就是说这行代码等价于 Integer i1=Integer.valueOf(40) 。因此,i1 直接使用的是缓存中的对象。而Integer i2 = new Integer(40) 会直接创建新的对象。
阿里开发手册这么说:

浅拷贝:浅拷贝会在堆上创建一个新的对象(区别于引用拷贝的一点),不过,如果原对象内部的属性是引用类型的话,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用同一个内部对象。
深拷贝 :深拷贝会完全复制整个对象,包括这个对象所包含的内部对象。
引用拷贝:两个不同的引用指向同一个对象。
public final class String implements java.io.Serializable, Comparable<String>, CharSequence {
private final char value[];
//...
}我们知道被 final 关键字修饰的类不能被继承,修饰的方法不能被重写,修饰的变量是基本数据类型则值不能改变,修饰的变量是引用类型则不能再指向其他对象。因此,final 关键字修饰的数组保存字符串并不是 String 不可变的根本原因,因为这个数组保存的字符串是可变的(final 修饰引用类型变量的情况)。
final int[] value={1,2,3}
int[] another={4,5,6};
value=another; //编译器报错,final不可变上述的方式直接改变引用是不允许的,但是我操作数据内部却是可以的
final int[] value={1,2,3};
value[2]=100; //这时候数组里已经是{1,2,100}所以String是不可变,关键是因为SUN公司的工程师,在后面所有String的方法里很小心的没有去动Array里的元素,没有暴露内部成员字段。private final char value[]这一句里,private的私有访问权限的作用都比final大。而且设计师还很小心地把整个String设成final禁止继承,避免被其他人继承后破坏。所以String是不可变的关键都在底层的实现,而不是一个final。
abstract class AbstractStringBuilder implements Appendable, CharSequence {
byte[] value;
}Java 9 为何要将 String 的底层实现由 char[] 改成了 byte[] ?
新版的 String 其实支持两个编码方案: Latin-1 和 UTF-16。如果字符串中包含的汉字没有超过 Latin-1 可表示范围内的字符,那就会使用 Latin-1 作为编码方案。Latin-1 编码方案下,byte 占一个字节(8 位),char 占用 2 个字节(16),byte 相较 char 节省一半的内存空间。
JDK 官方就说了绝大部分字符串对象只包含 Latin-1 可表示的字符。
泛型一般有三种使用方式:泛型类、泛型接口、泛型方法。
1.泛型类:
//此处T可以随便写为任意标识,常见的如T、E、K、V等形式的参数常用于表示泛型
//在实例化泛型类时,必须指定T的具体类型
public class Generic<T>{
private T key;
public Generic(T key) {
this.key = key;
}
public T getKey(){
return key;
}
}如何实例化泛型类:
Generic<Integer> genericInteger = new Generic<Integer>(123456);2.泛型接口 :
public interface Generator<T> {
public T method();
}实现泛型接口,不指定类型:
class GeneratorImpl<T> implements Generator<T>{
@Override
public T method() {
return null;
}
}3.泛型方法 :
public static < E > void printArray( E[] inputArray ){
for ( E element : inputArray ){
System.out.printf( "%s ", element );
}
System.out.println();
}使用:
// 创建不同类型数组: Integer, Double 和 Character
Integer[] intArray = { 1, 2, 3 };
String[] stringArray = { "Hello", "World" };
printArray( intArray );
printArray( stringArray );通常项目中使用范型:
自定义接口通用返回结果 CommonResult<T> 通过参数 T 可根据具体的返回类型动态指定结果的数据类型。
工厂模式:BeanFactory就是简单工厂模式的体现,用来创建对象的实例;
单例模式:Bean默认为单例模式。
代理模式:Spring的AOP功能用到了JDK的动态代理和CGLIB字节码生成技术;
模板方法:用来解决代码重复的问题。比如. RestTemplate, JmsTemplate, JpaTemplate。
观察者模式:定义对象键一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都会得到通知被制动更新,如Spring中listener的实现–ApplicationListener。
事务的隔离级别有四种:读未提交、读已提交、可重复读和可串行化。下表展示隔离级别解决的事务问题
| 隔离级别 | 脏读 | 不可重复读 | 幻读 |
|---|---|---|---|
| 读未提交 | ❌ | ❌ | ❌ |
| 读已提交 | ✅ | ❌ | ❌ |
| 可重复度 | ✅ | ✅ | ❌ |
| 可串行化 | ✅ | ✅ | ✅ |
读未提交
MySQL 事务隔离其实是依靠锁来实现的,加锁自然会带来性能的损失。而读未提交隔离级别是不加锁的,所以它的性能是最好的,没有加锁、解锁带来的性能开销。但有利就有弊,这基本上就相当于裸奔啊,所以它连脏读的问题都没办法解决。
举例:别人读到了你没还提交的数据修改结果,别人拿着结果走了,然后你回滚了。
缺陷:读到了别人没提交的数据
解决问题:没解决任何问题
读已提交
既然读未提交没办法解决脏数据问题,那么就有了读提交。读提交就是一个事务只能读到其他事务已经提交过的数据,也就是其他事务调用 commit 命令之后的数据。那脏数据问题迎刃而解了。读已提交只允许别人在提交后才能读这条数据。
举例:你要买电脑,可这时你媳妇正在购物,当你要提交订单时钱还够,输完密码说你余额不足
缺陷:你第一次查和第二次查结果不一样,别人写操作中,你可以进行读操作。
解决问题:别人提交前的数据你读不到了,解决了脏读
可重复读
可重复读是指,就是在开始读取数据(事务开启)时,不再允许修改操作。
举例:你花了2千元,然后你媳妇去查看你今天的消费记录(全表扫描FTS,妻子事务开启),看到确实是花了2千元,就在这个时候,你又花了1万买了一部电脑,即新增INSERT了一条消费记录,并提交。当你媳妇打印一下你的消费清单,发现花了1.2万元,似乎出现了幻觉,这就是幻读。
缺陷:重复读可以解决不可重复读问题。写到这里,应该明白的一点就是,不可重复读对应的是修改,即UPDATE操作。但是可能还会有幻读问题。因为幻读问题对应的是插入INSERT操作,而不是UPDATE操作。
解决问题:你在操作该条数据时别人无法操作,解决了不可重复读
可串行化 Serializable
Serializable 是最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读、不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。
为什么MySQL的默认隔离离别是RR?
binlog的格式也有三种:statement,row,mixed。设置为statement格式,binlog记录的是SQL的原文。又因为MySQL在主从复制的过程是通过binlog进行数据同步,如果设置为读已提交(RC)隔离级别,当出现事务乱序的时候,就会导致备库在 SQL 回放之后,结果和主库内容不一致。
什么是MVCC
MVCC全称是多版本并发控制 (Multi-Version Concurrency Control),只有在InnoDB引擎下存在。MVCC机制的作用其实就是避免同一个数据在不同事务之间的竞争,提高系统的并发性能。
它的特点如下:
允许多个版本同时存在,并发执行。
不依赖锁机制,性能高。
只在读已提交和可重复读的事务隔离级别下工作。
MVCC解决什么问题
在早期的数据库中,只有读读之间的操作才可以并发执行,读写,写读,写写操作都要阻塞,这样就会导致MySQL的并发性能极差。
采用了MVCC机制后,只有写写之间相互阻塞,其他三种操作都可以并行,这样就可以提高了MySQL的并发性能。
原理是什么
我们都知道,MySQL事务隔离级别有四种,分别是读未提交(Read Uncommitted,简称RU)、读已提交(Read Committed,简称RC)、可重复读(Repeatable Read,简称RR)、串行化(Serializable),只有RC和RR才跟MVCC机制相关,RU和Serializable都不会使用到MVCC机制。因为在读未提交(RU)级别下是直接返回记录上的最新值,Serializable级别下则会对所有读取的行都加锁。
实现 MVCC 要依赖:隐藏字段、Read View、Undo log
接下来要介绍几个mvcc的概念
ReadView
跟快照、snapshot是一个概念。可以理解为数据库中某一个时刻所有未提交事务的快照。ReadView 有几个重要的参数:
m_ids:表示生成ReadView时,当前系统正在活跃的读写事务的事务Id列表。
min_trx_id:表示生成ReadView时,当前系统中活跃的读写事务的最小事务Id。
max_trx_id:表示生成ReadView时,当前时间戳InnoDB将在下一次分配的事务id。
creator_trx_id:当前事务id。
所以当创建ReadView时,可以知道这个时间点上未提交事务的所有信息。
隐藏列
InnoDB存储引擎中,它的聚簇索引记录中都包含两个必要的隐藏列,分别是:
trx_id:事务Id,每次一个事务对某条聚簇索引记录进行改动时,都会把该事务的事务id赋值给trx_id隐藏列。
roll_pointer:回滚指针,每次对某条聚簇索引记录进行改动时,都会把旧的版本写入到undo log中,然后这个隐藏列就相当于一个指针,可以通过它来找到该记录修改前的信息。
事务链
每次对记录进行修改时,都会记录一条 undo log 信息,每一条 undo log 信息都会有一个 roll_pointer 属性(INSERT操作没有这个属性,因为之前没有更早的版本),可以将这些 undo 日志都连起来,串成一个链表。
RC和RR隔离级别的实现就是通过版本控制来完成,核心处理逻辑就是判断所有版本中哪个版本是当前事务可见的处理。两者最大的区别在于生成 ReadView 的时机的不同,RC级别生成 ReadView 的时机是每次查询都会生成新的ReadView,而RR级别是在当前事务第一次查询时生成,并且生成的 ReadView 会一直沿用到事务提交为止,保证可重复读。通过什么判断呢?就是上文讲到的ReadView,ReadView包含了当前系统活跃的读写事务的信息,判断的逻辑如下:
如果被访问版本的
trx_id属性值小于ReadView的最小事务Id,表示该版本的事务在生成 ReadView 前已经提交,所以该版本可以被当前事务访问。如果被访问版本的
trx_id属性值大于ReadView的最大事务Id,表示该版本的事务在生成 ReadView 后才生成,所以该版本不可以被当前事务访问。如果被访问版本的
trx_id属性值在ReadView的最小事务Id和最大事务Id之间,那就需要判断一下trx_id属性值是不是包含在m_ids列表中,如果包含的话,说明创建 ReadView 时生成该版本的事务还是活跃的,所以该版本不可以访问;如果不包含的话,说明创建 ReadView 时生成该版本的事务已经被提交,该版本可以被访问。
只有 RC 和 RR 的隔离级别才会使用 MVCC 机制,两者最大的区别在于生成 ReadView 的时机的不同,RC级别生成 ReadView 的时机是每次查询都会生成新的 ReadView,而RR级别是在当前事务第一次查询时生成,并且生成的 ReadView 会一直沿用到事务提交为止,保证可重复读。