
Collection
一、单列集合继承体系
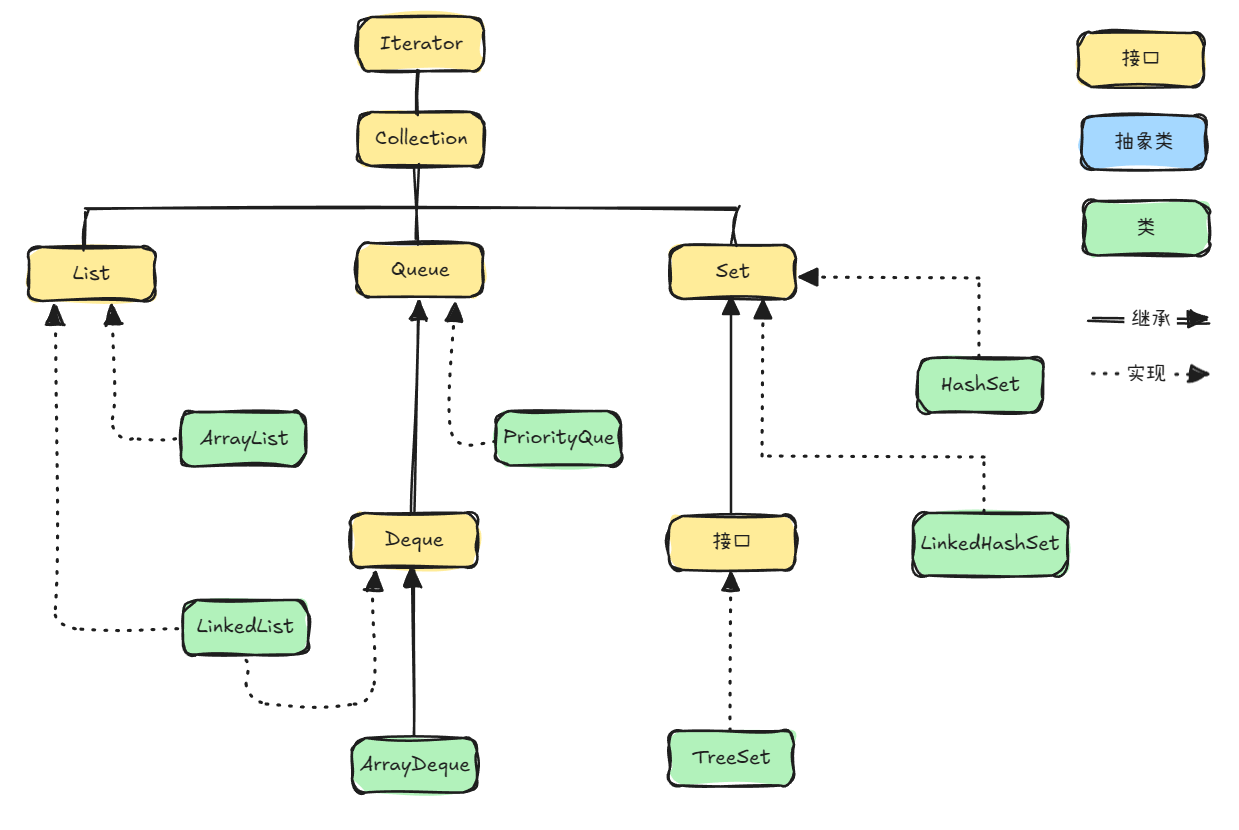
二、ArrayList、Vector和LinkedList的区别
索引数据速度快
两者都是基于 object[ ] array 来实现的,他们会在内存中开辟一段连续的空间,因此支持用序号(下标,索引)访问元素。
插入操作速度慢
插入元素的时候需要移动容器中的元素,所以执行速度比较慢。
ArrayList和Vector都有一个初始容量大小(大小为10),里面的元素超过容量的时候,就会自动扩容。为了提高效率,每次扩充容量的时候不是简单的扩充一个存储单元,而是扩充多个。
Vector默认扩充为原来的两倍(每次扩充大小可以设置),而ArrayList会扩充为原来的1.5倍(没有提供设置空间的方法)。
注意
public ArrayList() 在Java7之前和Java7不一样。
在Java7之前默认创建的是一个容量为10的数组 底层: this(10),而从Java7开始,默认创建的是一个没有元素的空数组 底层: new Object[]{}
虽然,此时创建的是一个没有元素的空数组,当第一次使用add()方法的时候,此时才设定初始容量为10。
线程安全问题
两者最大的区别就是(synchronization 同步)的使用,ArrayList没有一个方法是同步的,而Vector的绝大多数方法(如 add,insert,remove,set,equals,hashcode)都是直接或者间接同步的。所以,Vector是线程安全的,但是效率低,而ArrayList不是线程安全的,效率高。
LinkedList
LinkedList是采用的双向列表来实现的,对数据的索引需要从头来遍历,因此随机访问的效率低,但是插入的时候不需要移动元素,所以插入效率比较高。同时,LInkedList不是线程安全的。
三、Iterator 接口
iterator() 方法是Iterator接口的抽象方法,这个方法到底怎这么用呢?
在继承体系中的Collection的实现类中(这里拿ArrayList类举例)有一个内部类 class itr实现了 Iterator接口 而 ArrayList类中的iterator() 方法内部返回 itr 类的对象,也就是Iterator接口的实现类对象,所以可以用Iterator接口来接收;
用法
List<String> list=new ArrayList<>(); Iterator<String> it= list.iteratro();源码
public Iterator<E> iterator() { return new ArrayList.Itr(); } private class Itr implements Iterator<E> { ... }并发修改异常 ConcurrentModificationException
当遍历的时候修改集合的长度(添加元素或者删除元素),就会发生并发修改异常。
解决方式:使用迭代器。
注
迭代器有删除方法
it.remove()删除当前元素。没有添加方法,但是Iterator接口有一个子接口
ListIterator里面有add()方法。Iterator<String> iterator = list.iterator(); while(iterator.hasNext()){ String next = iterator.next(); char[] charArray = next.toCharArray(); for (char c : charArray) { if(c<'9'&&c>'0'){ iterator.remove();//用迭代器删 而不是 list.remove(next); break; } } } System.out.println(list);
四、双列集合体系
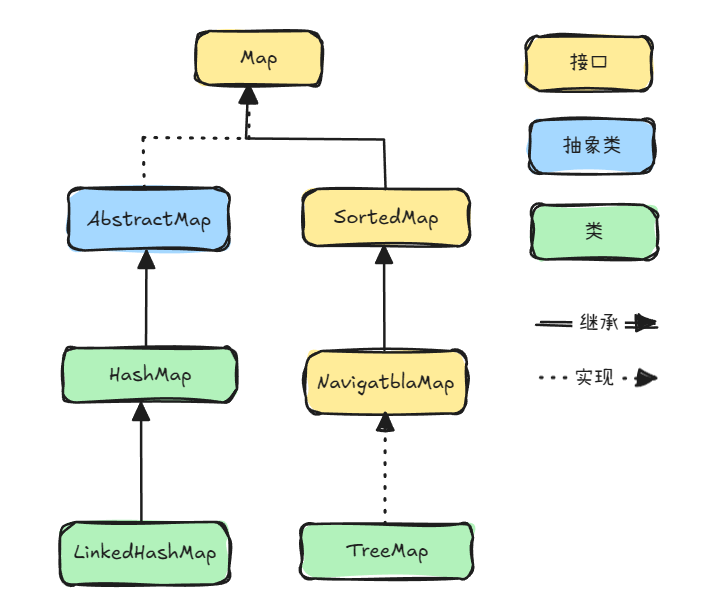
五、双列数据结构介绍
数学中有这么一个定义:有A和B两个集合,A集合中的一个元素,总能在B集合中找到唯一的一个映射值。B集合中的一个元素,可以被A集合中的多个元素映射。
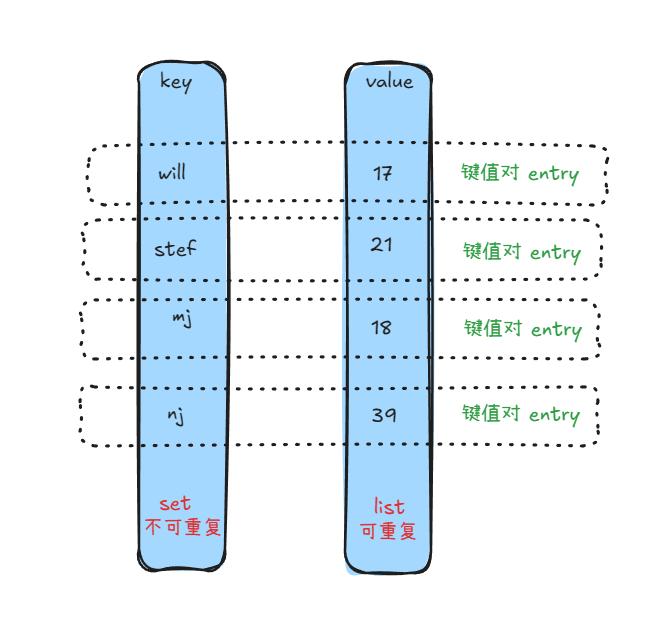
六、HashSet 和 HashMap
概述
通过观察Set和Map的体系,会发现很多实现类的名字相似(底层算法是相同的)。
拿HashSet和HashMap来举例。---> HashSet底层就是使用HashMap。
public HashSet(){ map=new HashMap<>(); } //Hashset底层源码非常少 //除了clone()、writeObject()、readObject()是自己不得不实现的之外,其他都是HashMap()的方法。把元素放在Set中时底层是放在了Map中;Map中的key就是Set的元素,所有key就是Set集合。
map如何遍历
//Map的迭代 //========================= /*不能使用for-each:for(Object o : map){}*/ //Set keySet(): 把Map中所有的key取出来,存放在set集合中 Set keys = map.keySet(); for(Object keyName : keys){ system.out.println(keyName + "," + map.get(keyName)); } System.out.println("--------------------"); // Collection values(): 把Map中的所有的value取出来,存放在Collection集合中 Collection values = map.values(); for(Object value : values){ System.out.println(value); } Sysout.out.println("---------------------"); //Set entrySet(): 把Map中的多个"key-value"(Entry),存放到Set集合中 Set entrys = map.entrySet(); for(Object obj : entrys){ Map.Entry entry = (Map.Entry)obs; System.out.println(entry); System.out.println(entry.getKey()); System.out.println(entry.getValue()); } //java8 map.forEach((k,v)->System.out.println("key : " + k + "; value : " + v));HashMap和HashTable
概述
Map有三个实现类HashMap、HashTable和 TreeMap。Map中用来索引的对象叫key,其对应的对象叫value。
HashMap是一个常用的Map。它根据键的HashCode 值来存储数据,根据键的值可接获取他的值,具有很快的访问速度。由于HashMap与HashTable都采用了Hash方行索引,所以有很多相似之处。
主要的区别
键值能否为空。
HashMap是HashTable的轻量级实现(非线程安全的实现),他们实现了Map接口,主要区别在于HashMap允许空键值NULL,但是最多允许空一条记录,而HashTable不允许空键值。hashMap 不能用get()方法判断是否存在某个键,因为可能不存在,可能存了null值。
方法的区别。
HashMap把HashTable的contains方法去掉了,改成了containsValue和containsKey。
继承的父类。
HashTable继承自Dictionary,HashMap是在java2引进的Map接口的实现。
线程安全问题。
HashTable是线程同步的,HashMap不支持线程同步,所以他的效率高,需要开发人员提供额外同步。
遍历。
HashTable通过Enumeration进行遍历,而HashMap用iterator来进行遍历。
扩容问题。
HashTable中的Hash数组默认大小是11,增加方式是old*2+1。在HashMap中,Hash数组的默认大小是16,而且一定是2的指数。
负载因子越小,查询效率越。因为负载因子小,数组上放的东西越稀疏,冲突的几率小,链表上挂的值越少,查询就快。
创建map时可以指定初始容量和负载因子,map数组部分的阈值=初始容量×负载因子,当数组的容量到达这个值就会扩容,扩容后的大小是初始容量的2倍。
HashMap使用"拉链法"解决冲突,当链表长度为8时,转换为红黑树。
JDK1.8之前
底层是 数组和链表 结合一起的链表散列。HashMap通过key的hashCode经过扰动函数 : 处理后得到的hash值,然后通过(n-1)&hash判断当前元素存放的位置(n指的数组长度),如果当前位置存在元素(发生hash冲突),首先判断该元素和要存放的元素的hash值以及key是否相同,相同则直接覆盖,不相同就采用拉链法解决。
//JDK1.8 static final int hash(Object key){ int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); // ^ 按位异或 >>> 无符号右移,忽略符号位,空位以0补齐 } //JDK1.7 static int hash(int h){ h ^= (h >>> 20) ^ (h >>> 12); return h ^ (h >>> 7) ^ (h >>> 4); }JDK1.8 以后
优化了解决hash冲突的方式:当链表长度大于阈值时(默认为8),将链表转化为红黑树,减少搜索时间。(转换前还会判断,如果当前数组长度小于64,会优先选择数组扩容)
注
TreeMap、TreeSet以及JDK1.8以后的HashMap底层都是红黑树,红黑树是为了解决二叉查找树的缺陷,因为二叉查找树某些情况下会形成线性结构。
七、选择集合使用问题
使用最多的是HashMap。在HashMap里面存入的键-值,在取出的时候没有固定顺序,是随机的。一般而言,Map中插入、删除、和定位元素,HashMap是最好的选择。
由于TreeMap实现了SortMap接口,能够把保存的元素根据键进行排序,所以,取出来是排好序的键-值 ,如果需要按自然顺序或者自定义顺序来遍历键,那么TreeMap是更好的选择。
LinkedHashMap是HashMap的子类,如果需要输出的顺序和输入的顺序一致,那么LInkedHashMap是更好的选择,它能按读取顺序来排列。
小技巧:在可以提前知道hashMap要放几个元素时,在创建HashMap时记得指定容量大小哦!